之前的文章有提到过,消费者大概是怎么做负载均衡的(集群模式),如下图所示:
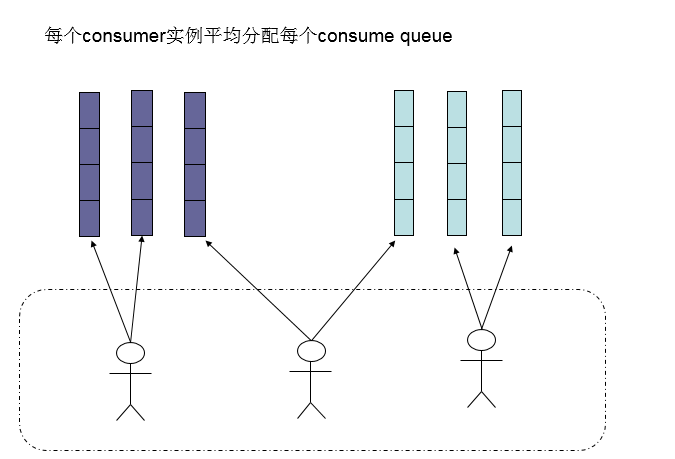
集群模式下,每个消费者实例会被分配到若干条队列。正因为消费者拿到了明确的队列,所以它们才能针对对应的队列做循环拉取消息的处理,以下是消费者客户端和broker通信的部分代码,可以看到通信的参数里有一个重要的参数,就是queueId
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
这侧面也再次印证,RocketMQ的消费模型是Pull模式。
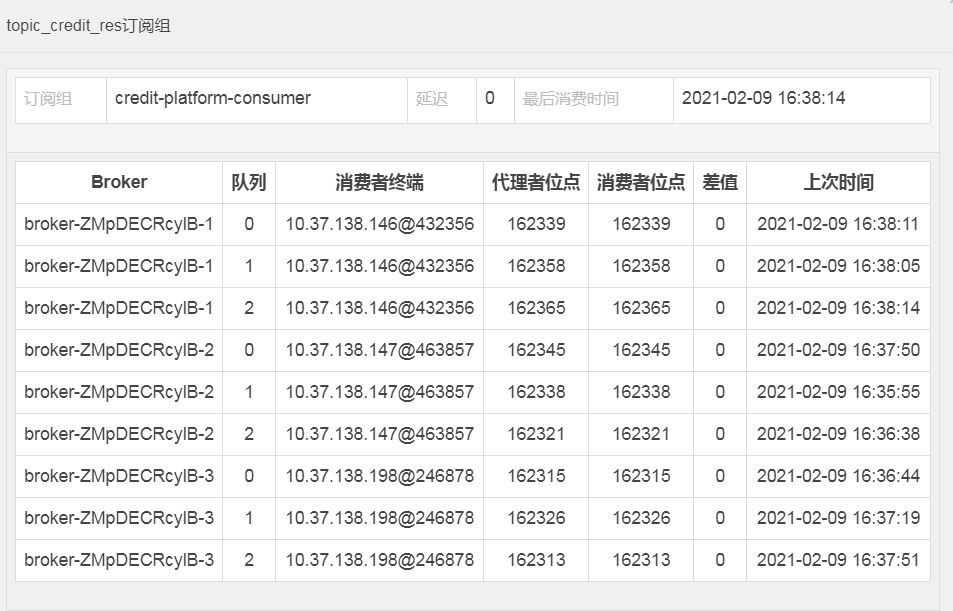
同时,对于每个消费者实例来说,在每个消息拉取之前,实际上都是确定了队列的(不会轻易发生改变),如下图控制台所示:
本文尝试对RocketMQ负载均衡(哪个消费者消费哪些队列)的原理进行解析,希望能让大家对其中的基本原理进行了解,并对部分问题能作出合理解析和正确规避。
所谓Rebalance到底在解决什么问题
RocketMQ每次分配队列的过程,代码里叫Relalance,本文在某些场景下也称为重排,实际上是一个负载均衡的过程。之所以说分配队列的过程就是负载均衡的过程的原因是,RocketMQ是负载均衡分配的就是队列,而不是消息。如果这个过程RocketMQ给了较高负载高,其实并不肯定意味着你能接受更多的消息(虽然绝大部分场景你可以这样理解),而只是说我给你分配了更多的队列。为什么说有更多的队列可能并不代表你有更多消息消费呢?
例如我们举一个例子,两个消费者一个消费者实例A获得了1个队列q0,一个消费者实例B获得了两个队列,这个负载均衡的过程分配了给B更多的”负载”(队列),但是假设消费者B获得的两个队列q1 q2中的q2本身是不可写的(topic可以配置读队列数量,写队列数量,所以是可能存在一些队列可读,但是不可写的情况),又或者生产者手动的选择了发送topic的queue目标(利用selector),这个过程从来都不选择q2,只有q0,和q1在做发送,甚至大部分情况下都往q0发,这时候消费者B实例其实都没有真正意义上的更高负载。
总结一下:就是所谓的消费者Rebalance,其实是分配队列的过程,它本质上希望解决的是一个消费者的负载问题,但是实际的工作其并不直接改变一个消费者实例的真实负载(消息),而是间接的决定的——通过管理分配队列的数量。而平时我们绝大部分可以认为队列的负载就是真实的消息负载的原因是基于这样一个前提:消息的分布基本是均匀分配在不同的队列上的,所以在这个前提下,获得了更多的队列实际上就是获得了更多的消息负载。
Relance具体是如何决定分配的数量的
RocketMQ的Rebalance实际上是无中心的,这和Kafka有本质区别,Kafka虽然也是客户端做的负载均衡,但是Kafka在做负载均衡之前会选定一个Leader,由这个Leader全局把控分配的过程,而后再把每个消费者对partion的分配结果广播给各个消费者。
而RocketMQ实际上没有人做这个统一分配的,而是每个消费者自己”有秩序地”计算出自己应该获取哪些队列,你可能会觉得很神奇,到底为啥大家能如此有秩序而不打架呢?我们下面来看看。
你可能知道RocketMQ是支持很多负载均衡的算法的,甚至还支持用户自己实现一个负载均衡算法。具体的这个分配算法需要实现以下接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
这个接口的getName()只是一个唯一标识,用以标识该消费者实例是用什么负载均衡算法去分配队列。
关键在于allocate这个方法,这个方法的出参就是这次Rebalace的结果——本消费者实例应该去获取的队列列表。
其余四个入参分别是:
1.消费者组名
2.当前的消费者实例的唯一ID,实际上就是client 的ip@instanceName。
3.全局这个消费者组可以分配的队列集合
4.当前这个消费者组消费者集合(值是消费者实例的唯一id)
试想下,假设要你去做一个分配队列的算法,实际上最关键的就是两个视图:1.这个topic下全局当前在线的消费者列表,2.topic在全局下有哪些队列。
例如,你知道当前有4个消费者 c1 c2 c3 c4在线,也知道topic 下有 8个队列 q0,q1,q2,q3,q4,…q6,那么8/4=2,你就能知道每个消费者应该获取两个队列。例如: c1–>q0,q1, c2–>q2,q3, c3–>q4,q5, c4–>q5,q6。
实际上,这就是rocketmq默认的分配方案。
但现在唯一的问题在于,我们刚刚说的,我们没有一个中心节点统一地做分配,所以RocketMQ需要做一定的修改。如对于C1:
“我是C1,我知道当前有4个消费者 c1 c2 c3 c4在线,也知道topic 下有 8个队列 q0,q1,q2,q3,q4,…q6,那么8/4=2,我就能知道每个消费者应该获取两个队列,而我算出来我要的队列是c1–>q0,q1”。
同理对于C2:
“我是C2,我知道当前有4个消费者 c1 c2 c3 c4在线,也知道topic 下有 8个队列 q0,q1,q2,q3,q4,…q6,那么8/4=2,我就能知道每个消费者应该获取两个队列,而我算出来我要的队列是c2–>q2,q3。
要做到无中心的完成这个目标,唯一需要增加的输入项就是“我是C1”,”我是C2”这样的入参,所以上文提到的allocate方法下面当前的消费者实例的唯一ID就是干这个事用的。以下是一个默认的策略,本人添加了中文注释,以达到的就是上文例子中的分配结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
Rebalance是怎么对多Topic做分配
细心地你可能会提一个问题,上面的提到的策略分配接口里,没有Topic的订阅关系的信息,那么如果一个消费者组订阅了topic1也订阅了topic2,topic下的队列数量可能是不一样的,那么最后分配的结果肯定也是不同的,那么怎么分配的呢?
答案是:一次topic的分配就单独调用一次分配接口,每次rebalance,实际上都会被RebalanceImpl里的rebalanceByTopic调用,而每订阅一个topic就会调用rebalanceByTopic,从而触发一次上文讲到的分配策略
Rebalance什么时候触发
其实看完上文,我们已经知道RocketMQ客户端是怎么无中心地做队列分配的了。现在还有一个问题,就是这个触发时机是什么时候?
为什么触发时机很重要呢?试想一下,突然间假设有一个消费者实例扩容了,从4个变成5个。如果有一个实例以5个去做负载均衡,其他四个老消费者以为在线的消费者还是只有四个,最后分配的结果肯定是会有重复的(某些情况甚至会漏分配),所以这个“节奏”很重要。
简单地来说,RocketMQ有三个时机会触发负载均衡:
启动的时候,会立即触发
有消费实例数量的变更的时候。broker在接受到消费者的心跳包的时候如果发现这个实例是新的实例的时候,会广播一个消费者数量变更的事件给所有消费者实例;同理,当发现一个消费者实例的连接断了,也会广播这样的一个事件
- 定期触发(默认20秒)。
第一个时机很好理解。启动的时候,消费者需要需要知道自己要分配什么队列,所以要触发Rebalance。
第二个时机实际也很好理解。因为有实例的数量变更,所以分配的结果肯定也需要调整的,这时候就要广播给各消费者。
第三点定期触发的原因实际上是一个补偿机制,为了避免第二点广播的时候因为网络异常等原因丢失了重分配的信号,或者还有别的场景实际上也需要重新计算分配结果(例如队列的数量变化、权限变化),所以需要一个定时任务做补偿。
从以上的触发时机可以看出,大部分情况下,消费者实例应该都是“节奏一致的”,如果出现异常场景或某些特殊场景,也会因为定时任务的补偿而达到最终一致的状态。所以如果你发现消费者分配有重复/漏分,很有可能这个消费者有短暂异常,没有及时地触发Rebalance,这个也可以从客户端日志中看出问题以便具体排查:如果一个消费者负载均衡后发现自己的分配的队列发生了变化:会有类似的日志(每一个Topic都会单独打印):
1
| |
从而判断是否及时地触发了负载均衡。
注:虽然每次Rebalance都会触发,但是如果重新分配后发现和原来已分配的队列是一致的,并不会有实际的重排动作。如:上次分配的是q0,q1,这次分配的也是q0,q1意味着整体的外部状态并没有修改,是不会有真正的重排动作的,这时候在日志上并不会有所表现。
Rebalance可能会到来消息的重复
实际上,Rebalance如果真的发现前后有变化(重排),这是一个很重的操作。因为它需要drop掉当前分配的队列以及其中的任务,还需要同步消费进度等。而由于这个过程比较长,且很可能每个消费者实际drop队列和分配队列是不一致的,所以通常情况下,重排都意味着有消息的重复投递。所以消费者端必须要做好消费的幂等。
我们不妨假设这样一个分配过程:A1本来拥有q0,这次重排需要拿q1,A2本来拥有q1,这次重排不需要q1了。那么对于A2来说,他首先要做的是:把q1的任务中断(drop队列),然后在合适的时机把q1的消费进度同步一下,再重新分配(这个例子这里不太重要),同样的A1也是要经历一样的过程:把q0的任务中断(drop队列),然后在合适的时机把q0的消费进度同步一下,然后重新分配——拿到q1。
我们假设A1的过程比A2要快,这里有两个可能:
1.一种情况是A1在A2把q1队列drop掉之前,A1就又拿到了q1,所以在这个时间窗口上观察,你会发现q1短暂地同时分配给了A1和A2。而由于RocketMQ的消费模型是Pull模式,所以A1、A2会同时拉取消息,消息就重复了。
2.另一种情况可能性更大,A2的确drop掉了队列不拉取了,但是消费进度(假设为OF1)还没及时同步到broker。那么A1拿到了q1之后,他需要第一时间知道自己从哪里(位点)拉取消息,所以他会询问一次broker,而broker这时候他的信息也是落后的,就会返回一个较老的消息位点OF2,那么[OF2,OF1]之间的消息就会重复。
可以看到,光负载均衡的这个实现原理,就会导致RocketMQ消息重复比一般的消息中间件概率要大,而且严重不少(消息是批量重复的)。