最近在学习MySQL的优化,今天整理下一些对于开发人员有必要了解的一些技巧。
关于索引
很多SQL优化都和索引有关,所以,在了解SQL优化前,最好先理解什么是索引,索引做的是什么。关于这点,stackoverflow上有很好的一个问题:how does database indexing work。
简单说,索引就是把数据库中的字段进行了一定规则的建立额外的排序,使得SQL查找可以快速找到所需的数据块,避免全表搜索。
关于如何建立索引,以下有一张图可以给出一个较好的指导:
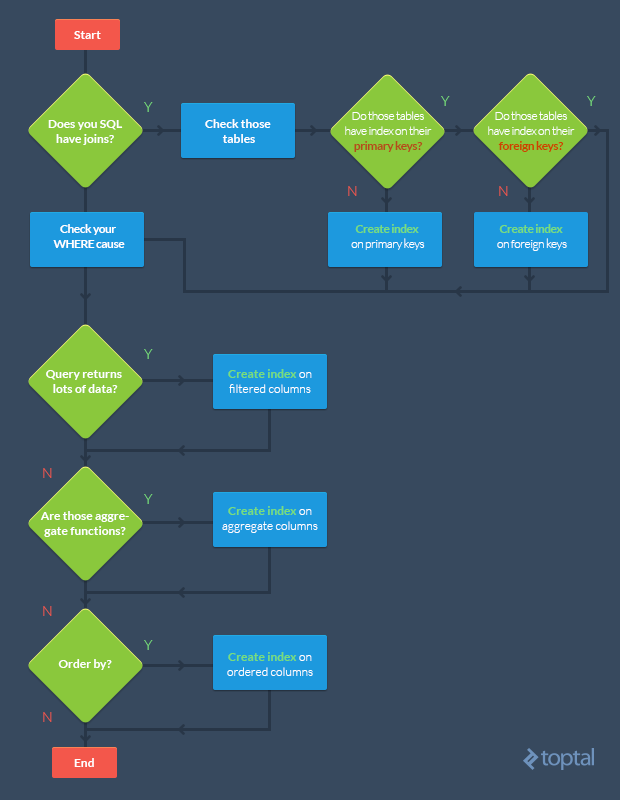
索引列相关的SQL优化技巧
- 避免在索引列使用通配符%开头
如(’%.com’),这将会令MySQL无法使用改列索引,而使用%结尾则可以(如’www.%‘)使用索引。
如果需要经常基于某索引列作以通配符开头的查询,如查询所有.com结尾的ip email like '%.com',可以在数据库中保存改列的反序值(如reverse_email),然后搜索的时候使用 reverse_email like REVERSE('%.com'),则可以使用到reverse_email的索引了。
- 避免在索引列使用函数或者计算
如 where trunc(create_date)=trunc(:date1)这样的where 条件将无法使用到create_date的索引。
避免在索引列上出现数据类型转换
避免在索引字段上使用not,<>
其他技巧:
- 尽量避免使用相关子查询
如:
SELECT c.Name,
c.City,
(SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName
FROM Customer c
其中子查询 SELECT CompanyName....的结果与外层查询结果相关,这样会导致每一个外层查询的结果都会返回到子查询中查询一遍,导致性能下降。这种子查询大多可以改造为表的join:
SELECT c.Name,
c.City,
co.CompanyName
FROM Customer c
LEFT JOIN Company co
ON c.CompanyID = co.CompanyID
- 避免循环中使用SQL
如:
//查询满足
SELECT a.id,a.author_id,a.title //找出满足某条件的文章的作者
FROM article a
WHERE a.type=2
AND a.created> '2011-06-01';
//For 循环这些记录,然后查询作者信息,
select id, name,age
from arthor where id=:author_id
这类问题常被称作N+1问题,即每对应外层的每一行都生成了一条SQL语句,这导致了很多的SQL语句重复执行。
这种SQL通常也可以通过join而被改写为单条SQL语句:
SELECT a.id, a.title,au.author_id,au.author_name,au.age
FROM artitle a
INNER JOIN author au on a.author_id = au.id
WHERE a.type=2
AND a.created> '2011-06-01';
- 不要使用SELECT *
使用SELECT * 有很多的坏处,例如:
- 选择过多的列导致不必要的开销。有些时候我们只需要两列,但select * 会把所有的列(可能20列)全部返回,这是额外的IO开销。
- SELECT * 不容易针对化的建立索引。由于不知道该 SQL语句中具体需要哪些列,就很难针对化的设计所需的索引。而且,即便按照所有的列都设计了索引,一旦表结构发生了增加列的情况,此索引也会失效,而且后来的人很难发觉。
- MySQL 引擎需要解释*所代表的列,也会带来一定的开销
更多相关讨论可以参考:why is select * considered harmful
- 拆分大的INSERT/DELETE语句
如果有一个很大批量的INSERT/DELETE(需要锁表)语句需要执行,例如对几十万行的语句执行,可以考虑分量的一批一批执行,每次执行完后放开CPU,这样可以避免阻塞其他线程的操作。如:
while (1) {
//每次只做1000条
pst.execute("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000");
if row return 0 {
// 没得可删了,退出!
break;
}
// 每次都要sleep一段时间让出CPU
sleep(50000);
}
- 当只需要一行数据的时候,使用LIMIT 1
当你查询表的有些时候,如果我们知道只会有一条结果,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。 请看下面伪代码:
// 没有效率的:
result_set= ps.execute_query("SELECT user_name FROM user WHERE country = 'China'");
if (result_set.hasNext()) {
// ...
}
//更好效率的:
result_set= ps.execute_query("SELECT user_name FROM user WHERE country = 'China' LIMIT 1");
if (result_set.hasNext()) {
// ...
}
- 避免在WHERE子句中使用in,not in
可以使用 exist 和not exist代替 in和not in。
//低效
SELECT order_id,order_num,customer_name FROM ORDERS WHERE CUSTOMER_NAME NOT IN
(SELECT CUSTOMER_NAME FROM CUSTOMER)
//高效
SELECT order_id,order_num,customer_name FROM ORDERS WHERE not exist
(SELECT CUSTOMER_NAME FROM CUSTOMER where CUSTOMER.customer_name = ORDERS.customer_name)
关于缓存
在MySQL中使用缓存把查询结果保留能有效减小SQL查询时间
在应用程序中使用缓存
如:
IF CACHE NOT EMPTY
SELECT FROM CACHE
IF CACHE EMPTY
SELECT TABLE
PUT INTO CACHE
但需要注意一旦表发生了改变,需要移除CACHE的相关数据。
注:
可用流行的memcached框架缓存查询结果,减小数据库压力。